My name is Youjia Zhang (张由甲), a PhD Student at the School of Computer Science and Technology, Huazhong University of Science and Technology, in the HUST Media Lab, advised by Prof. Wei Yang. My research focuses on the intersection of Computer Vision, Graphics, and Neural Rendering.
Experience
- 2026.05 - Present,
 Research Scientist Intern, Meshy AI.
Research Scientist Intern, Meshy AI. - 2025.09 - 2026.04,
 Visiting Student at Anpei Chen’s Group, Westlake University.
Visiting Student at Anpei Chen’s Group, Westlake University.
Services
- Conference Reviewer: CVPR, ECCV, ICCV, NeurIPS, ICLR, ICML, SIGGRAPH Asia, ICME, AISTATS, ICASSP.
- Journal Reviewer: TPAMI
Publications
Equal contribution$^\star$ Corresponding author$^\dagger$

LATO.2: Factorized 3D Mesh Generation with Vertex and Topology Flow
Hang Long*, Tianhao Zhao*, Junkai Lin, Youjia Zhang, Huipeng Guo, Rendong Liang, Jiale Xu, Jozef Hladký, Matthias Nießner, Yuanming Hu, Wei Yang †
- We present LATO.2, a factorized flow-based framework for 3D mesh generation that disentangles continuous geometry and discrete topology. By modeling vertices and connectivity through separate but coordinated generation processes, LATO.2 enables high-fidelity mesh synthesis, scalable part-wise generation, and topology-aware editing.
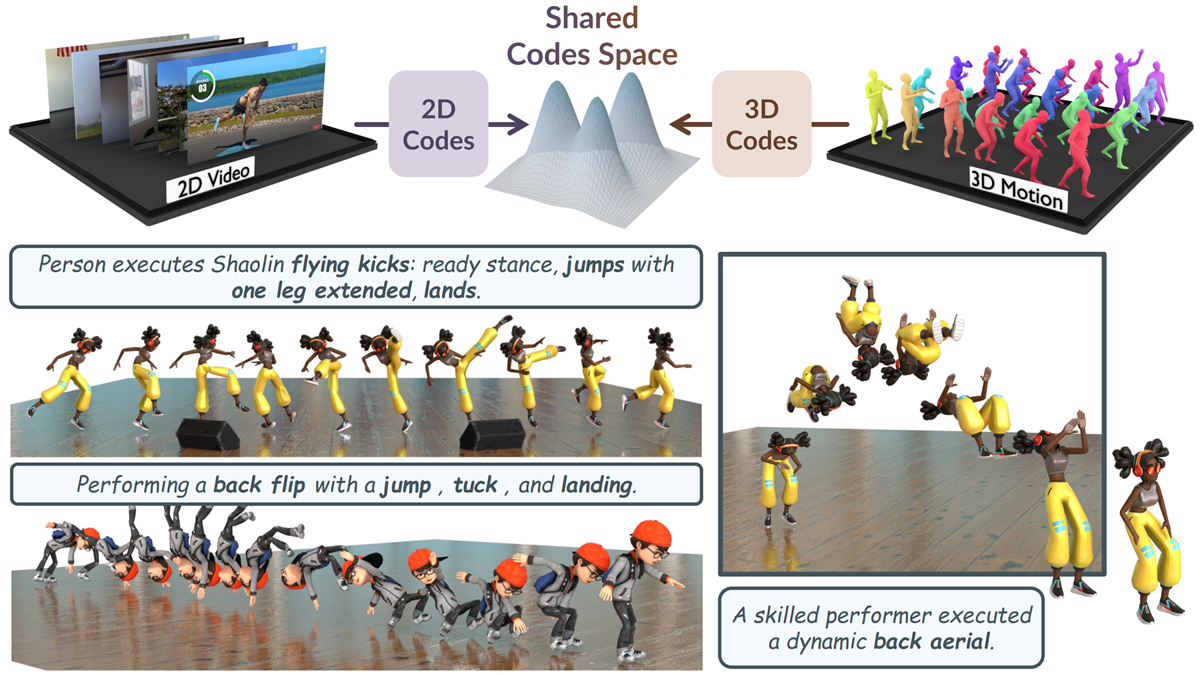
MoVT: Video-Augmented Motion Tokenizer for Text-to-Motion Generation
Beibei Jing, Tianle Guo, Youjia Zhang, Zikai Song, Yawei Luo, Junqing Yu, Tao Guan, Wei Yang †
ACM International Conference on Multimedia (ACMMM), 2026
- We propose MoVT, a cross-modal motion tokenization framework that addresses the limited diversity of 3D motion data by exploiting large-scale human videos. MoVT learns enriched motion representations through 2D–3D token alignment and enables a more powerful masked transformer for text-conditioned 3D human motion generation.
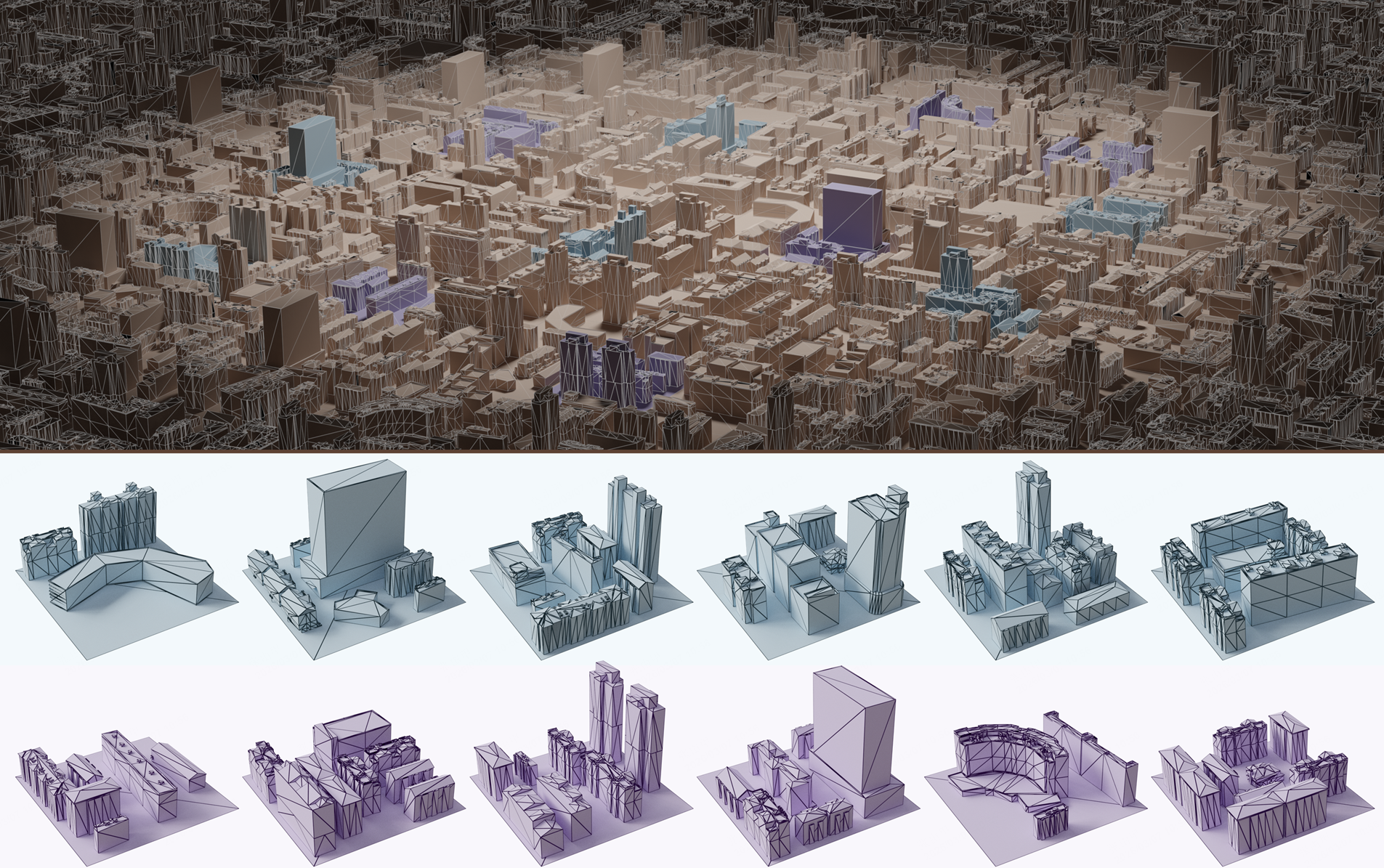
LATO: 3D Mesh Flow Matching with Structured TOpology Preserving LAtents
Tianhao Zhao*, Youjia Zhang*, Hang Long, Jinshen Zhang, Wenbing Li, Yang Yang, Gongbo Zhang, Jozef Hladký, Matthias Nießner, Wei Yang †
International Conference on Machine Learning (ICML), 2026
- We introduce LATO, a topology-preserving latent representation for scalable flow-matching-based generation of explicit 3D meshes. LATO encodes a mesh as a surface-anchored Vertex Displacement Field and reconstructs vertices through progressive voxel subdivision and pruning. For generation, LATO uses a two-stage flow matching process that first synthesizes structural voxels and then refines voxel-wise topology features.
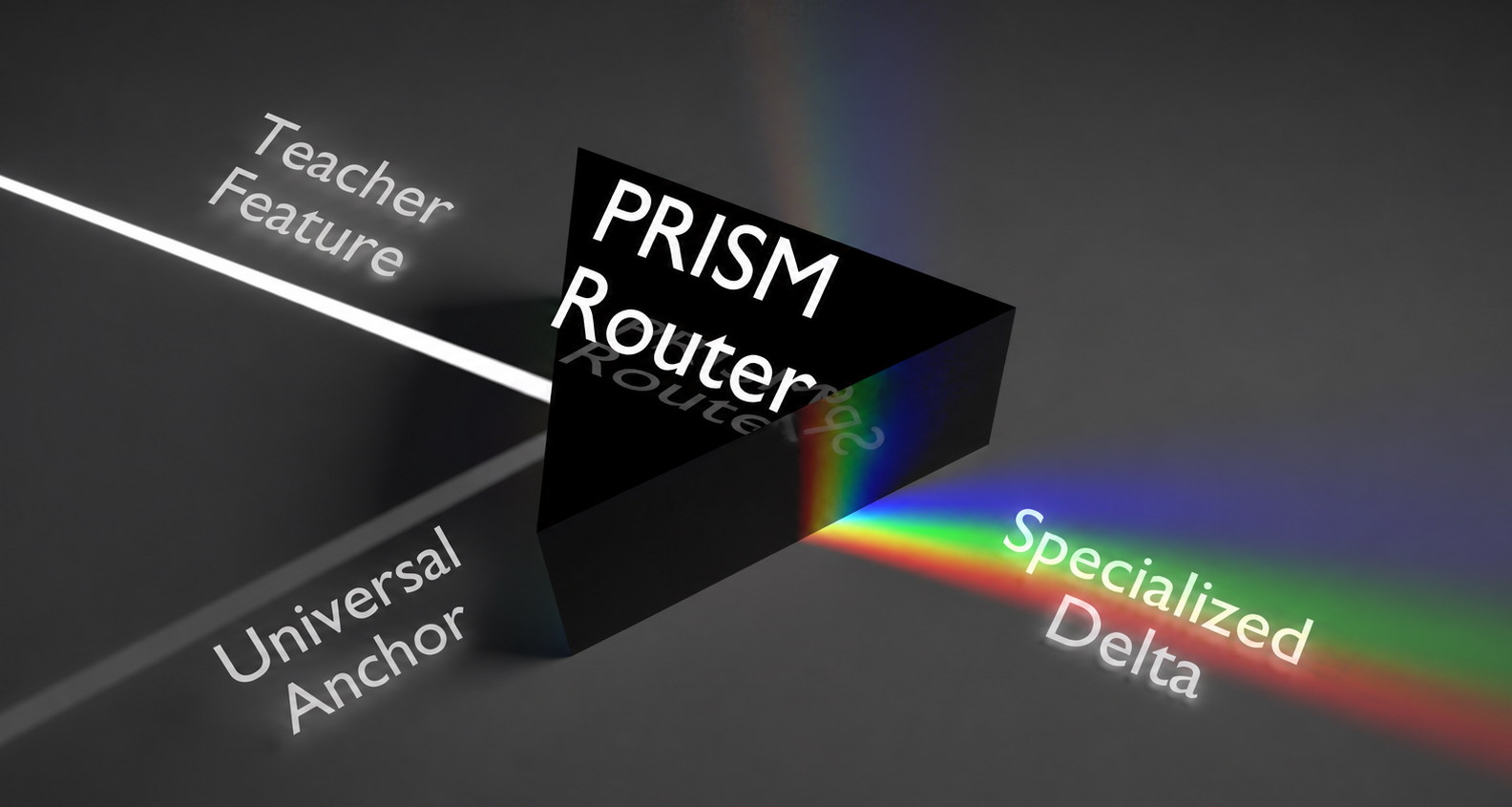
PRISM: Synergizing Vision Foundation Models via Self-organized Expert Specialization
Ying Tang, Dong Li, Youjia Zhang, Zikai Song, Junqing Yu, Wei Yang †
International Conference on Machine Learning (ICML), 2026
- We introduce PRISM, a dual-stream Mixture-of-Experts framework synergizing VFMs via a two-stage paradigm: expertise deconstruction for interference-free expert specialization, and dynamic recomposition for task-specific routing.
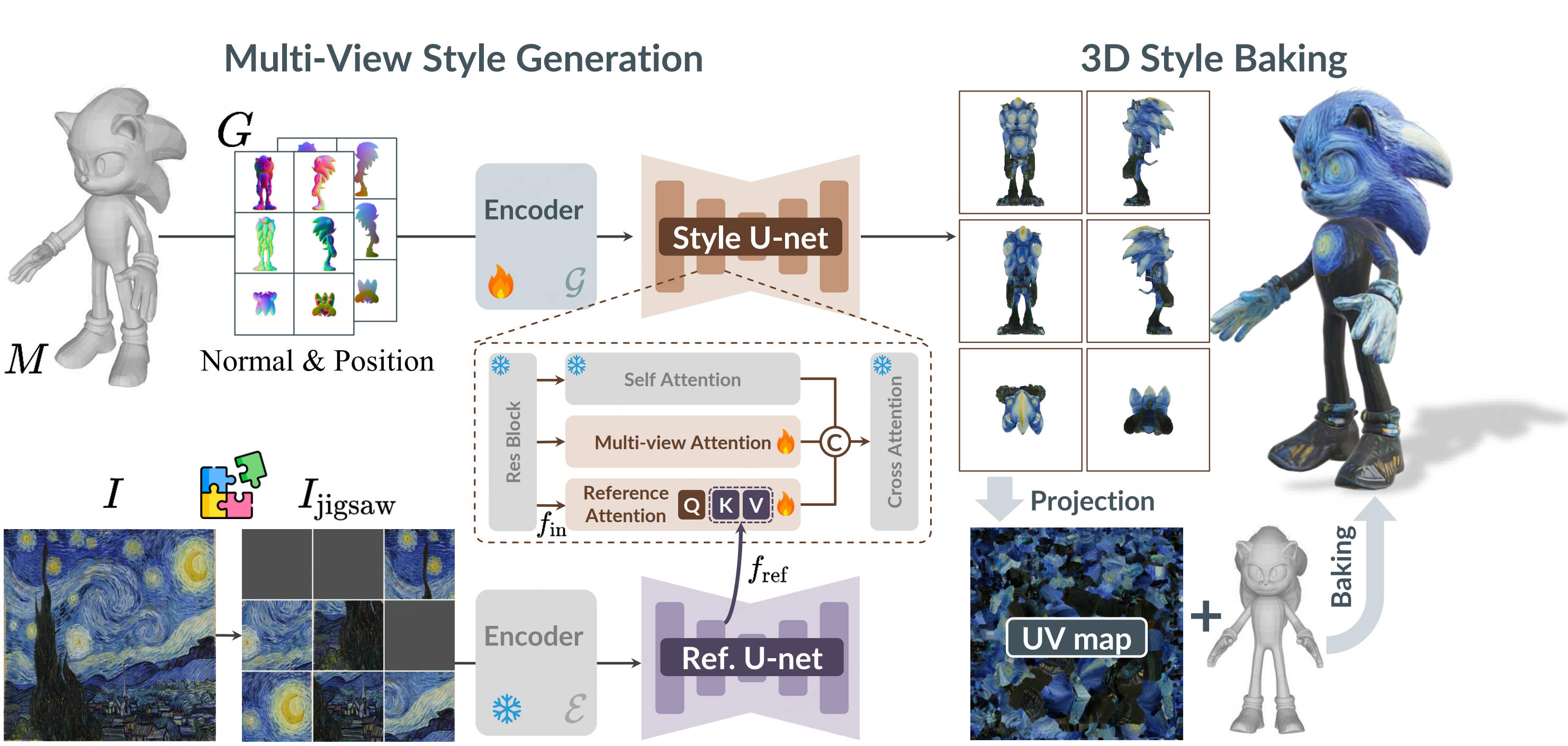
Jigsaw3D: Disentangled 3D Style Transfer via Patch Shuffling and Masking
Yuteng Ye, Zheng Zhang, Qinchuan Zhang, Di Wang, Youjia Zhang, Wenxiao Zhang, Wei Yang, Yuan Liu †
- We propose Jigsaw3D, a framework for 3D style transfer consisting of a jigsaw operation to isolate style statistics, a multi-view diffusion model with reference-to-view cross-attention, and a style-baking step to produce view-consistent textures.

Motion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
Hongyuan Chen, Xingyu Chen, Youjia Zhang, Zexiang Xu, Anpei Chen †
Computer Vision and Pattern Recognition (CVPR), 2026
- We present Motion 3-to-4, a feed-forward framework for monocular 4D object synthesis that decomposes dynamic geometry into canonical shape generation and motion reconstruction, learning compact motion latents to predict temporally coherent vertex trajectories.

Ref-GS: Directional Factorization for 2D Gaussian Splatting
Youjia Zhang, Anpei Chen †, Yumin Wan, Zikai Song, Junqing Yu, Yawei Luo, Wei Yang †
Computer Vision and Pattern Recognition (CVPR), 2025
Project | Paper | Code | Slides | Poster
- Ref-GS builds upon the deferred rendering of Gaussian splatting and applies directional encoding to the deferred-rendered surface, effectively reducing the ambiguity between orientation and viewing angle. We introduce a spherical Mip-grid to capture varying levels of surface roughness, enabling roughness-aware Gaussian shading.
Optimized View and Geometry Distillation from Multi-view Diffuser
Youjia Zhang, Zikai Song, Junqing Yu, Yawei Luo, Wei Yang †
International Joint Conference on Artificial Intelligence (IJCAI), 2025
- We propose the USD, which achieves consistent single-to-multi-view synthesis and geometry recovery by using a radiance-field consistency prior and Unbiased Score Distillation—injecting unconditioned 2D diffusion noise to debias optimization—followed by a two-step, object-aware denoising process that yields high-quality views for accurate geometry and texture.
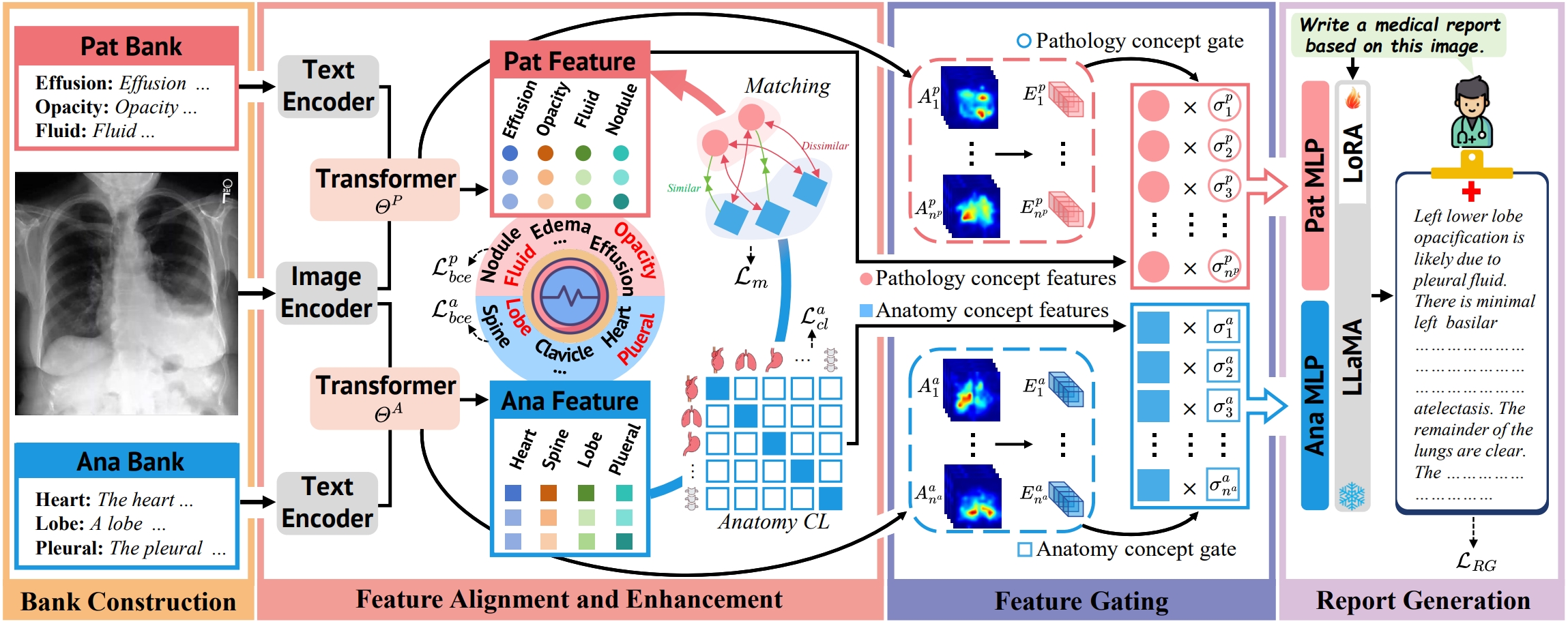
MCA-RG: Enhance LLM with Medical Concept Alignment for Radiology Report Generation
Qilong Xing, Zikai Song, Youjia Zhang, Na Feng, Junqing Yu, Wei Yang †
Medical Image Computing and Computer Assisted Intervention (MICCAI), 2025
- We propose MCA-RG, a knowledge-driven framework for radiology report generation that aligns visual features with curated pathology and anatomy concept banks, employs contrastive and matching losses, and leverages feature gating to guide accurate, clinically relevant report synthesis.
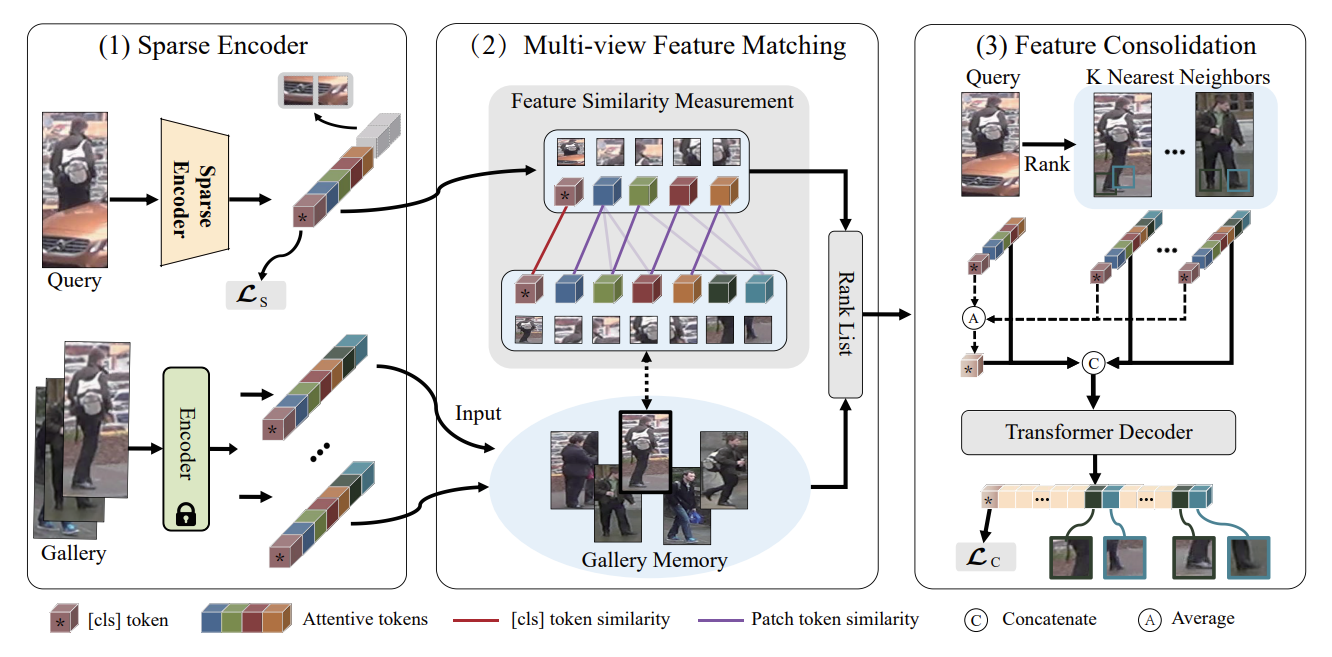
Dynamic feature pruning and consolidation for occluded person re-identification
YuTeng Ye, Jiale Cai, Chenxing Gao, Youjia Zhang, Junle Wang, Qiang Hu, Junqing Yu, Wei Yang †
AAAI Conference on Artificial Intelligence (AAAI), 2024
- We propose a Feature Pruning and Consolidation (FPC) framework to circumvent explicit human structure parse, which consists of a sparse encoder, a global and local feature ranking module, and a feature consolidation decoder.
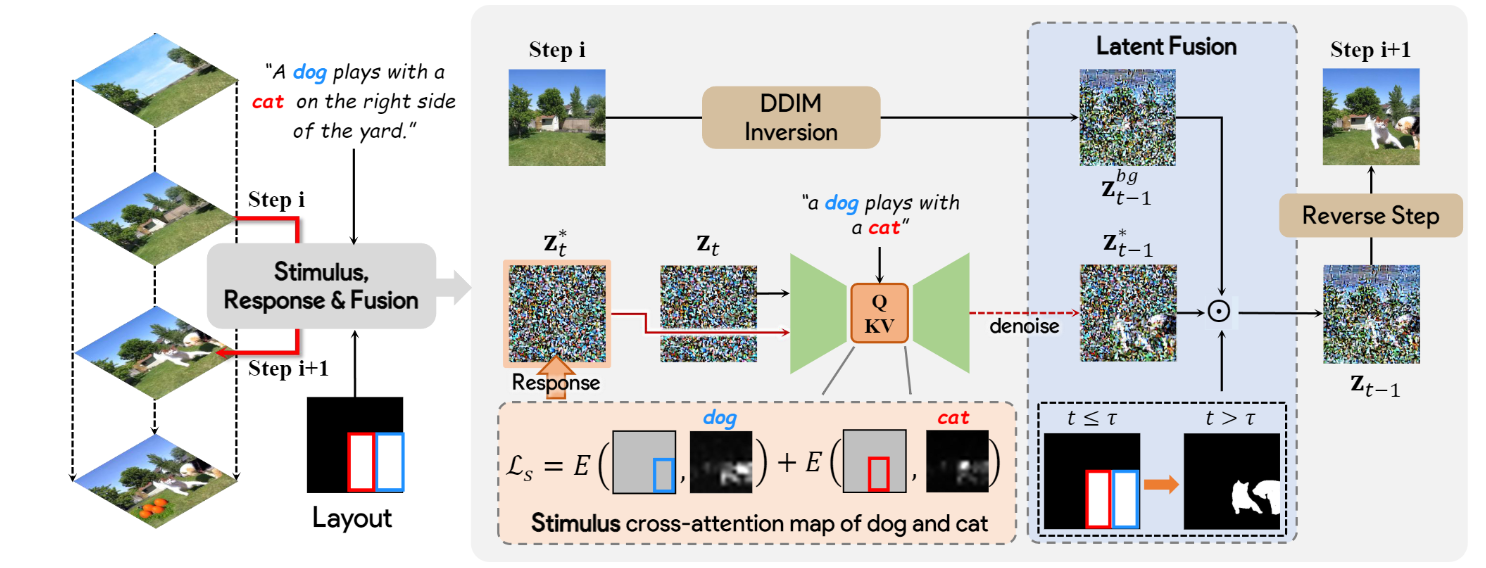
Progressive Text-to-Image Diffusion with Soft Latent Direction
YuTeng Ye, Jiale Cai, Hang Zhou, Guanwen Li, Youjia Zhang, Zikai Song, Chenxing Gao, Junqing Yu, Wei Yang †
AAAI Conference on Artificial Intelligence (AAAI), 2024
- We propose to harness the capabilities of a Large Language Model (LLM) to decompose text descriptions into coherent directives adhering to stringent formats and progressively generate the target image.
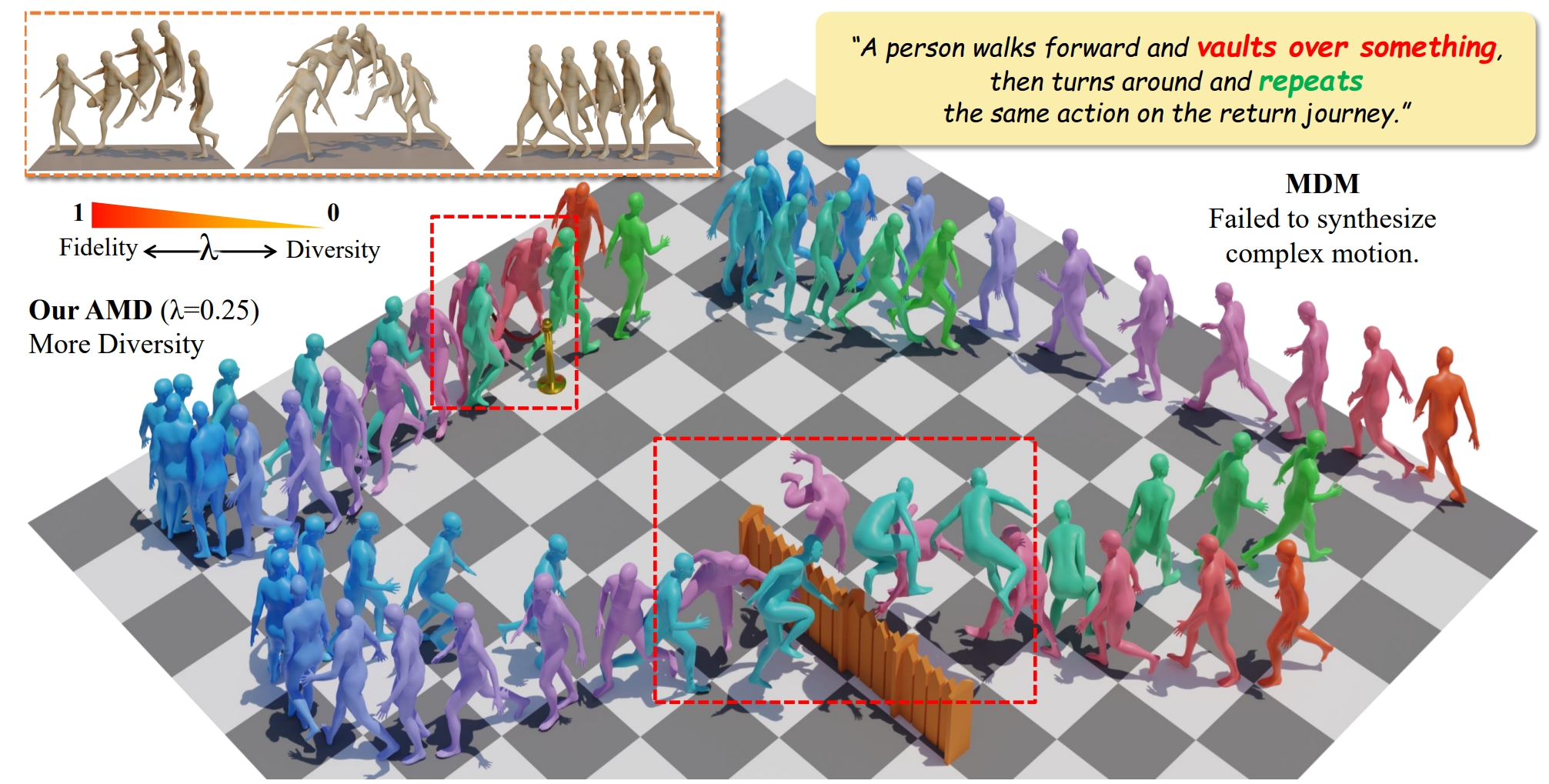
AMD: anatomical motion diffusion with interpretable motion decomposition and fusion
Beibei Jing, Youjia Zhang, Zikai Song, Junqing Yu, Wei Yang †
AAAI Conference on Artificial Intelligence (AAAI), 2024
- We propose the Adaptable Motion Diffusion (AMD) model, which leverages a Large Language Model (LLM) to parse the input text into a sequence of concise and interpretable anatomical scripts that correspond to the target motion.
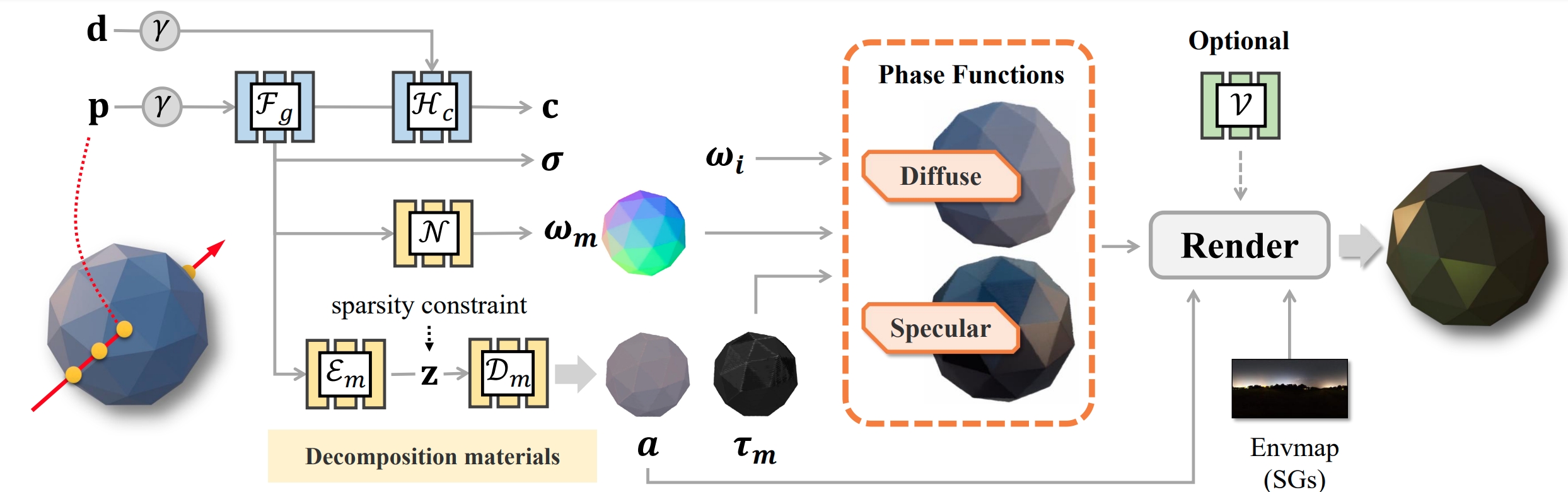
NeMF: Inverse volume rendering with neural microflake field
Youjia Zhang, Teng Xu, Junqing Yu, Yuteng Ye, Yanqing Jing, Junle Wang, Jingyi Yu, Wei Yang †
International Conference on Computer Vision (ICCV), 2023
- We propose to conduct inverse volume rendering by representing a scene using microflake volume, which assumes the space is filled with infinite small flakes and light reflects or scattersat each spatial location according to microflake distributions.

Highly accurate and large-scale collision cross sections prediction with graph neural networks
Renfeng Guo*, Youjia Zhang*, Yuxuan Liao*, Qiong Yang, Ting Xie, Xiaqiong Fan, Zhonglong Lin, Yi Chen, Hongmei Lu †, Zhimin Zhang †
Nature Communications Chemistry (JCR-Q1), 2023
- We present SigmaCCS, a graph neural network-based method for CCS prediction from 3D conformers. It achieves high accuracy and chemical interpretability, enabling large-scale in-silico CCS estimation.
Honors and Awards
- 2026: Meshy AI Fellowship 2026 Outstanding Prize Recipient.
- 2023: China National Scholarship (Top 1%).
- 2021: Outstanding Graduates of Central South University.
Educations
- 2017.09 - 2021.06, Undergraduate, Central South University.
- 2021.09 - 2023.06, Master, Huazhong University of Science and Technology.
- 2023.09 - Present, Ph.D, Huazhong University of Science and Technology.