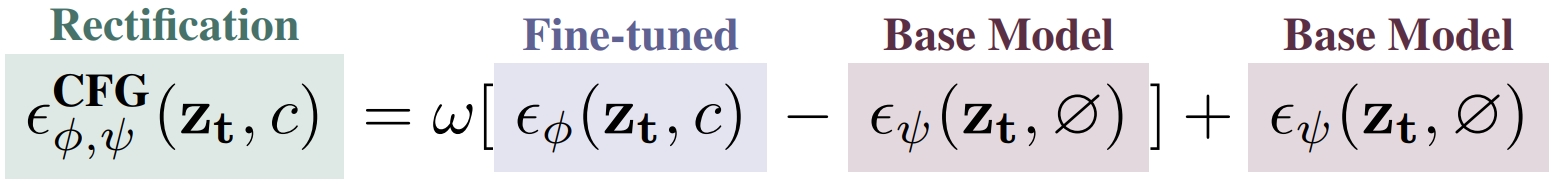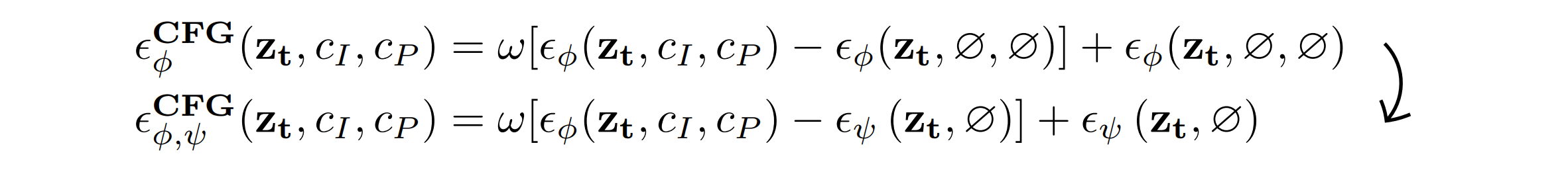Abstract
Our technique produces multi-view images and geometries that are comparable, sometimes superior particularly for irregular camera poses, when benchmarked against concurrent methodologies such as SyncDreamer and Wonder3D, without training on large-scale data
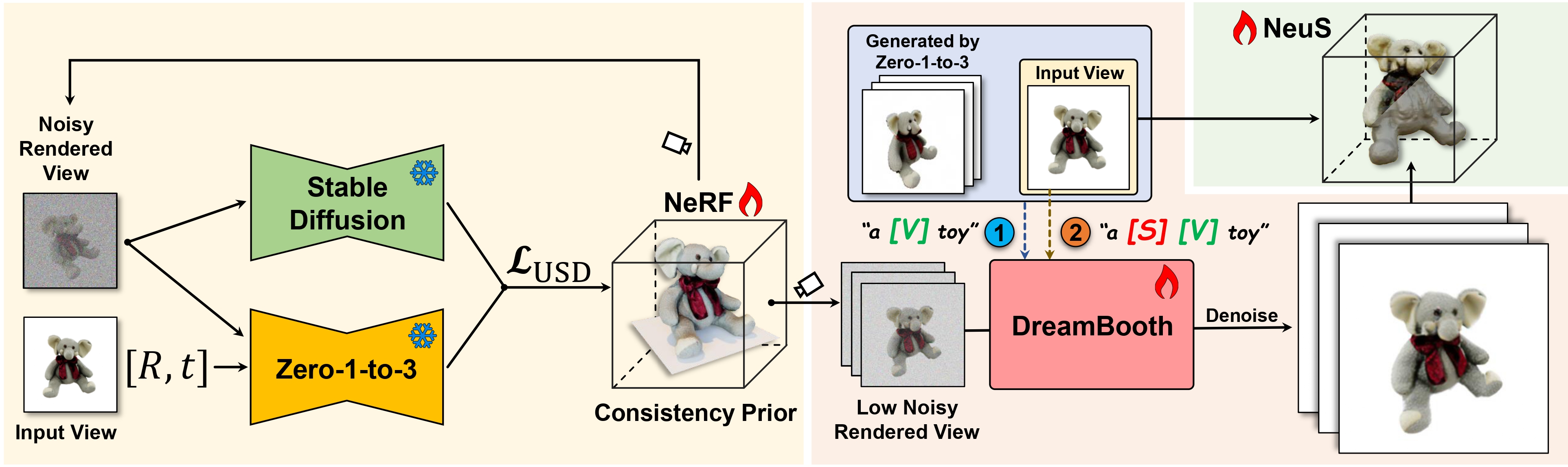
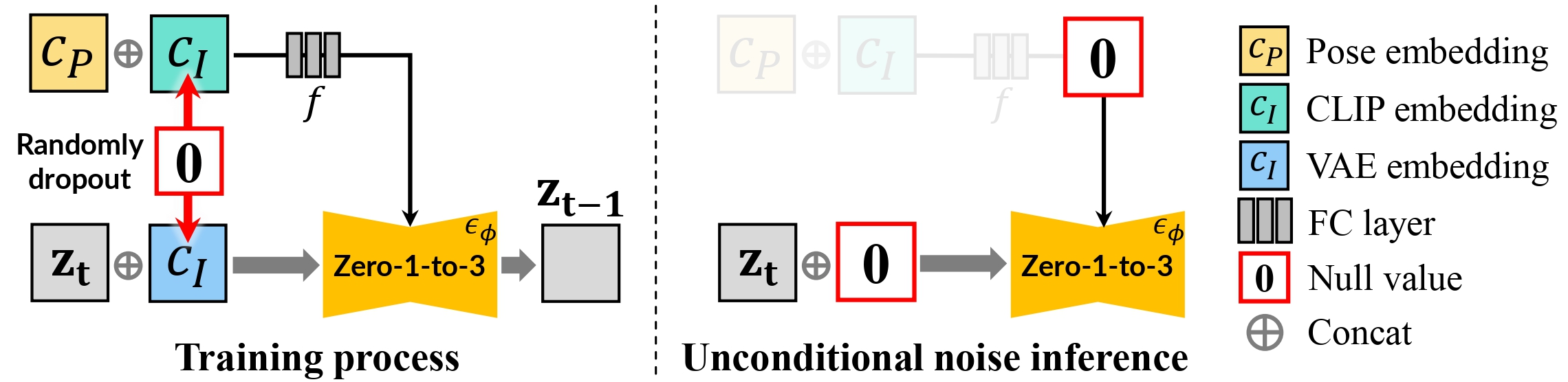
Generating multi-view images from a single input view using image-conditioned diffusion models is a recent advancement and has shown considerable potential. However, issues such as the lack of consistency in synthesized views and over-smoothing in extracted geometry persist. Previous methods integrate multi-view consistency modules or impose additional supervisory to enhance view consistency while compromising on the flexibility of camera positioning and limiting the versatility of view synthesis. In this study, we consider the radiance field optimized during geometry extraction as a more rigid consistency prior, compared to volume and ray aggregation used in previous works. We further identify and rectify a critical bias in the traditional radiance field optimization process through score distillation from a multi-view diffuser. We introduce an Unbiased Score Distillation (USD) that utilizes unconditioned noises from a 2D diffusion model, greatly refining the radiance field fidelity. We leverage the rendered views from the optimized radiance field as the basis and develop a two-step specialization process of a 2D diffusion model, which is adept at conducting object-specific denoising and generating high-quality multi-view images. Finally, we recover faithful geometry and texture directly from the refined multi-view images. Empirical evaluations demonstrate that our optimized geometry and view distillation technique generates comparable results to the state-of-the-art models trained on extensive datasets, all while maintaining freedom in camera positioning.